
Text-to-Image diffusion models have made tremendous progress over the past two years, enabling the generation of highly realistic images based on open-domain text descriptions. However, despite their success, text descriptions often struggle to adequately convey detailed controls, even when composed of long and complex texts. Moreover, recent studies have also shown that these models face challenges in understanding such complex texts and generating the corresponding images. Therefore, there is a growing need to enable more control modes beyond text description. In this paper, we introduce Uni-ControlNet, a novel approach that allows for the simultaneous utilization of different local controls (e.g., edge maps, depth map, segmentation masks) and global controls (e.g., CLIP image embeddings) in a flexible and composable manner within one model. Unlike existing methods, Uni-ControlNet only requires the fine-tuning of two additional adapters upon frozen pre-trained text-to-image diffusion models, eliminating the huge cost of training from scratch. Moreover, thanks to some dedicated adapter designs, Uni-ControlNet only necessitates a constant number (i.e., 2) of adapters, regardless of the number of local or global controls used. This not only reduces the fine-tuning costs and model size, making it more suitable for real-world deployment, but also facilitate composability of different conditions. Through both quantitative and qualitative comparisons, Uni-ControlNet demonstrates its superiority over existing methods in terms of controllability, generation quality and composability.
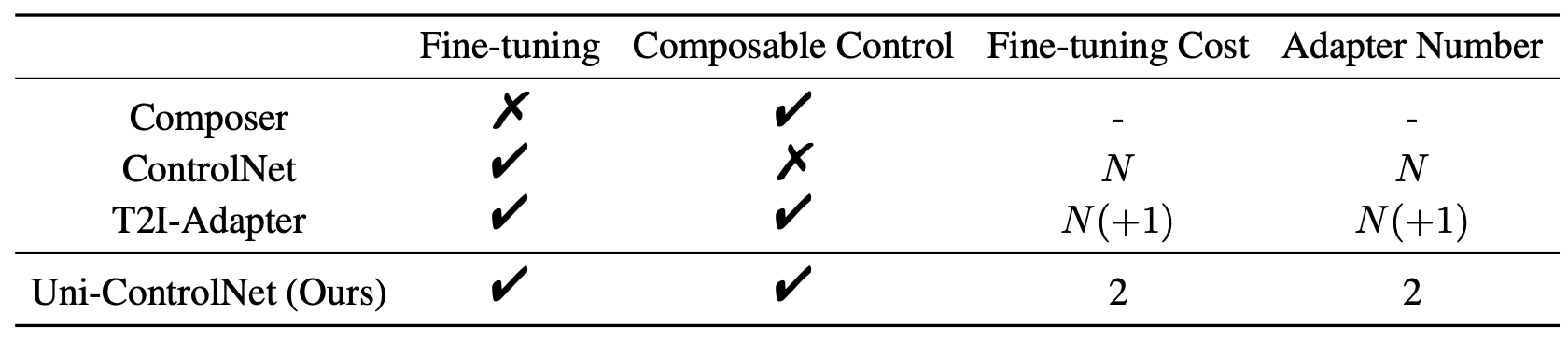
Comparisons of different controllable diffusion models. N is the number of conditions.
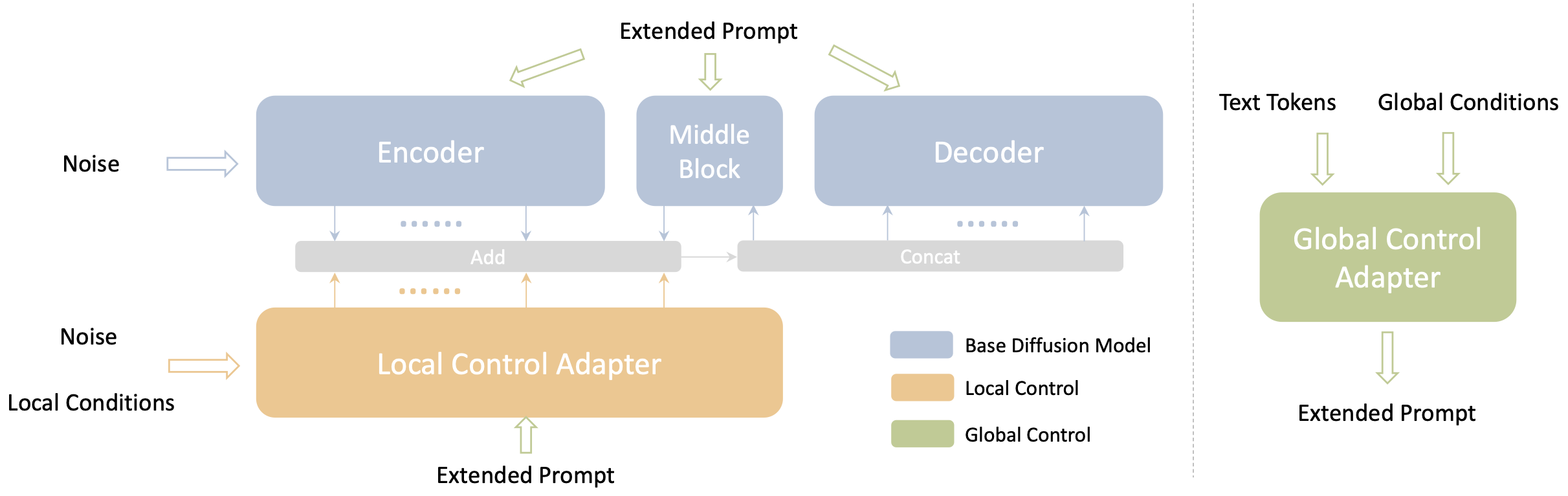
Uni-ControlNet categorizes various conditions into two distinct groups: local conditions and global conditions. Accordingly, two additional adapters are added: local control adapter and global control adapter.
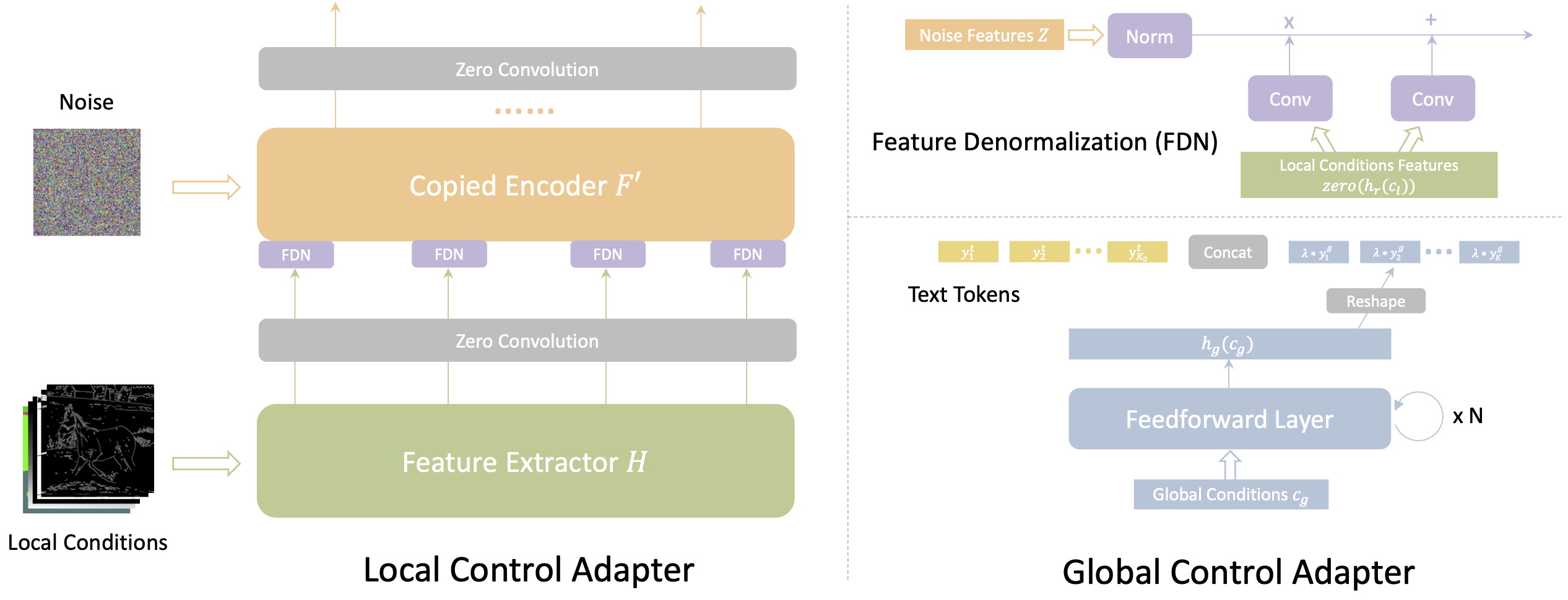
For local controls, we introduce a multi-scale condition injection strategy that uses a shared local condition encoder adapter. And for global controls, we employ another shared global condition encoder to convert them into conditional tokens, which are then concatenated with text tokens. These two adapters can be separately trained without the need of additional joint training.

More visual results of Uni-ControlNet for single condition setting.
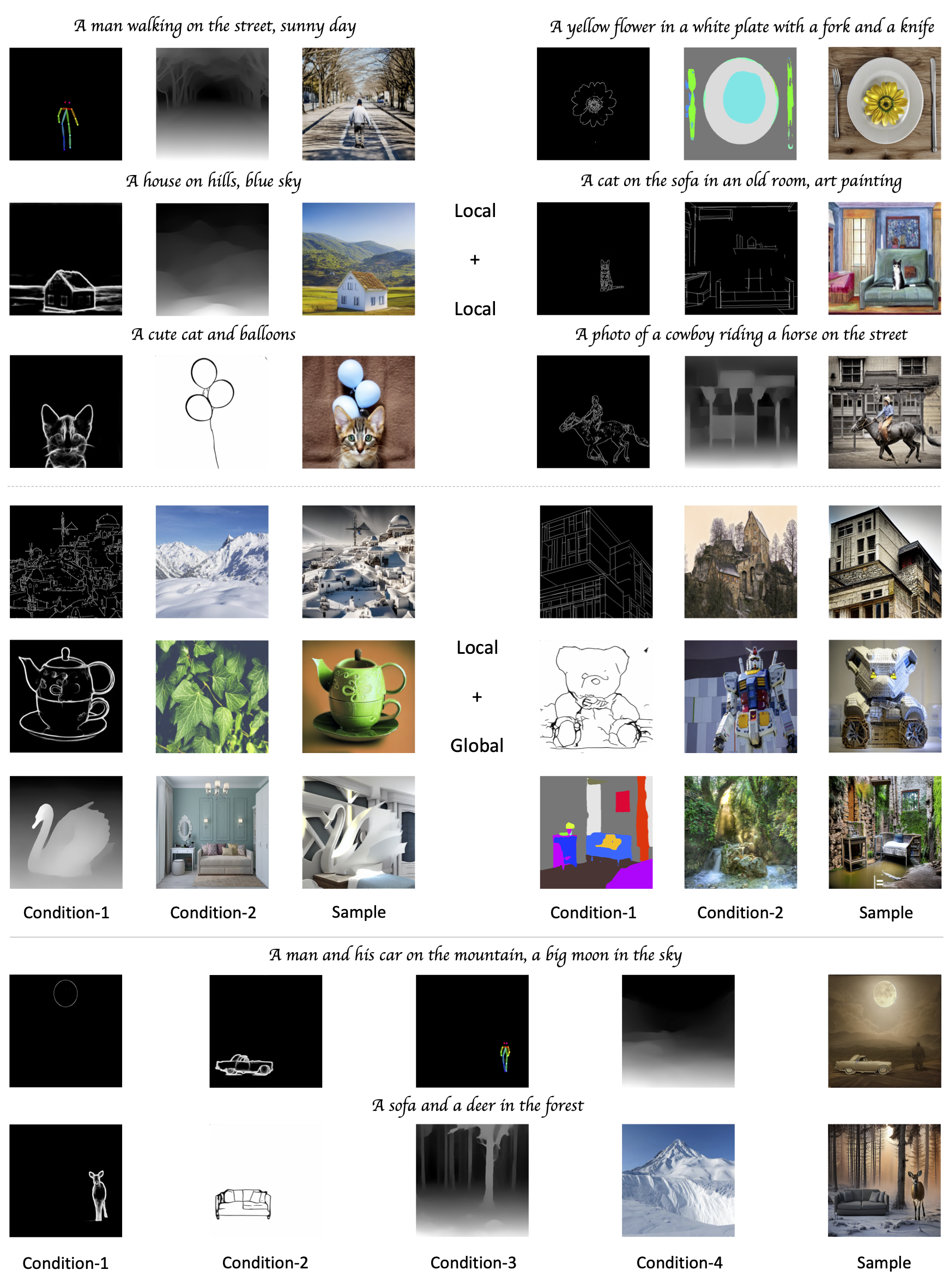
More visual results of Uni-ControlNet for multi-conditions setting.
@article{zhao2023uni,
title={Uni-ControlNet: All-in-One Control to Text-to-Image Diffusion Models},
author={Zhao, Shihao and Chen, Dongdong and Chen, Yen-Chun and Bao, Jianmin and Hao, Shaozhe and Yuan, Lu and Wong, Kwan-Yee~K.},
journal={Advances in Neural Information Processing Systems},
year={2023}
}