LaVi-Bridge is designed for text-to-image diffusion models and serves as a bridge, capable of connecting various pre-trained language models and generative vision models.
Text-to-image generation has made significant advancements with the introduction of text-to-image diffusion models. These models typically consist of a language model that interprets user prompts and a vision model that generates corresponding images. As language and vision models continue to progress in their respective domains, there is a great potential in exploring the replacement of components in text-to-image diffusion models with more advanced counterparts. A broader research objective would therefore be to investigate the integration of any two unrelated language and generative vision models for text-to-image generation. In this paper, we explore this objective and propose LaVi-Bridge, a pipeline that enables the integration of diverse pre-trained language models and generative vision models for text-to-image generation. By leveraging LoRA and adapters, LaVi-Bridge offers a flexible and plug-and-play approach without requiring modifications to the original weights of the language and vision models. Our pipeline is compatible with various language models and generative vision models, accommodating different structures. Within this framework, we demonstrate that incorporating superior modules, such as more advanced language models or generative vision models, results in notable improvements in capabilities like text alignment or image quality. Extensive evaluations have been conducted to verify the effectiveness of LaVi-Bridge.
The language and vision models in the text-to-image diffusion models become closely intertwined after training on a large dataset of text-image pairs. This tight coupling ensures a strong alignment between the provided text description and the generated image, but at the same time also limits the flexibility of the diffusion model. Decoupling the language and vision modules in existing text-to-image diffusion models and replacing a module with a new one becomes nontrivial.
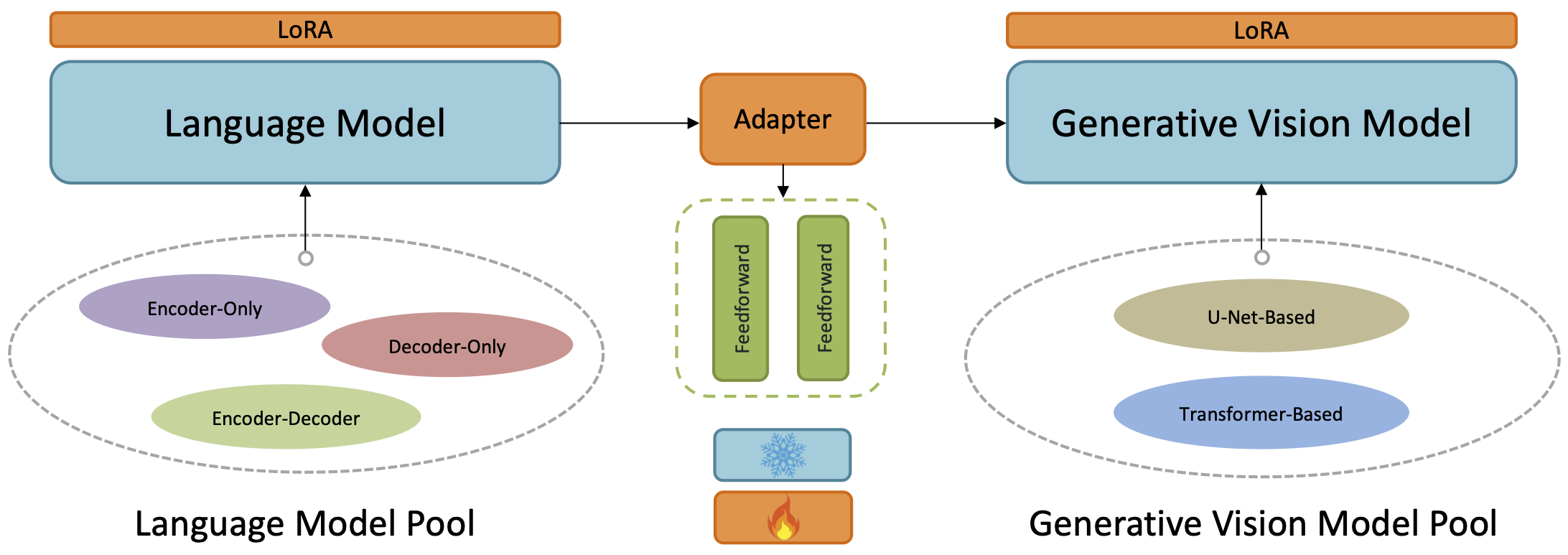
To establish a connection between two unrelated language and vision models that have not been previously trained together, LaVi-Bridge keeps the pre-trained language and vision models fixed and utilizes LoRA to introduce trainable parameters into both the language model and the vision model. Furthermore, LaVi-Bridge introduces an adapter as a bridge between the language model and vision model to facilitate better alignment.
We fixed the vision model to the U-Net of Stable Diffusion V1.4 and train LaVi-Bridge with different language models. We considered CLIP text encoder, based on the encoder-only framework, T5 series (T5-Small, T5-Base, T5-Large), based on the encoder-decoder framework, and Llama-2-7B, based on the decoder-only framework. Here are the visualization results:

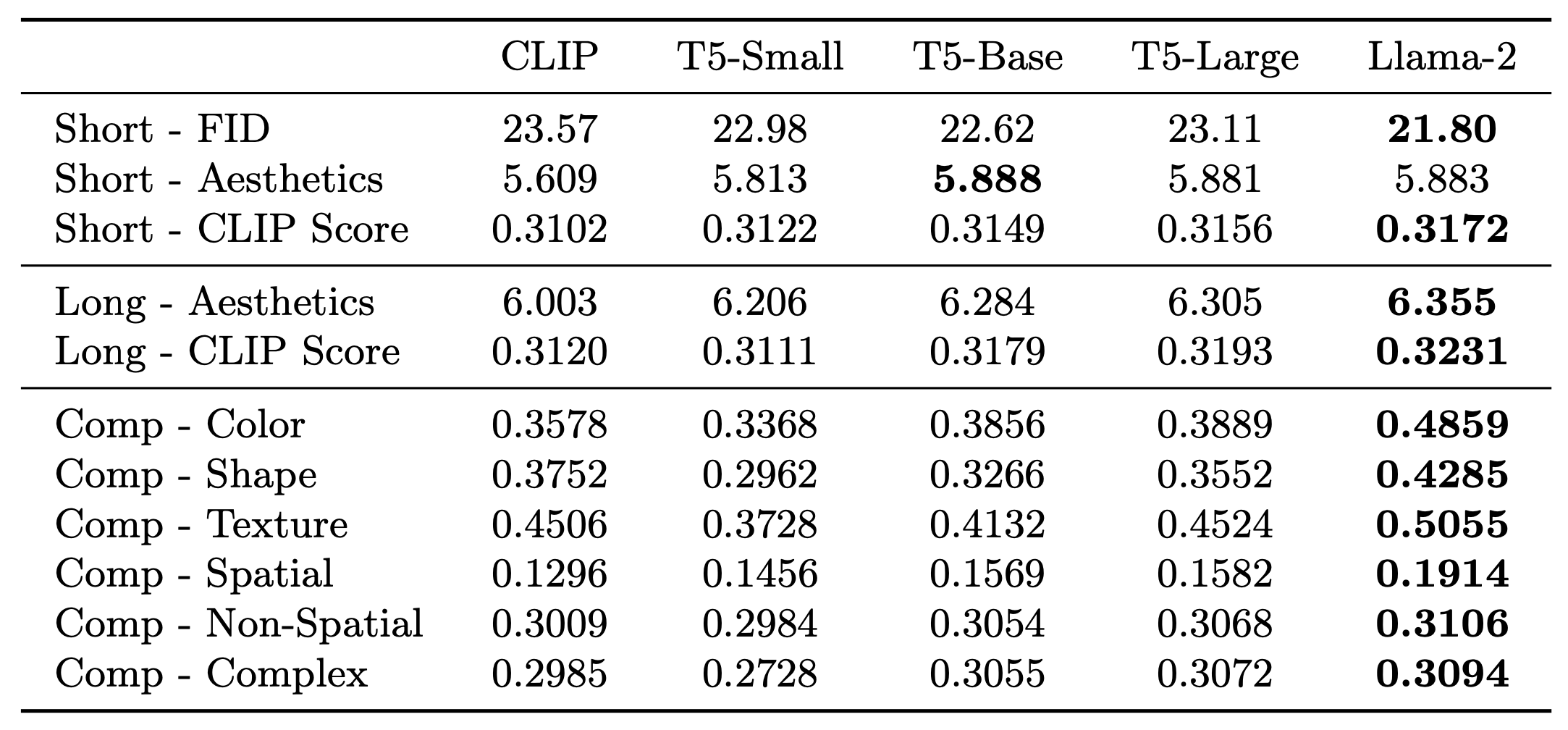
We conducted the quantitative evaluation on short prompts, long prompts, and compositional prompts for LaVi-Bridge with different language models. The results are shown in the following table. We can observe that, for all the metrics used to evaluate text alignment ability, Llama-2 achieves the best results, T5-Large is superior to T5-Base, and T5-Base is superior to T5-Small.
We fixed the language model to T5-Large and integrated it with different generative vision models under LaVi-Bridge. We considered the well-trained U-Nets in the Latent Diffusion Model and Stable Diffusion V1.4, as well as the Vision Transformer in PixArt, totally three models. Here are the visualization results:

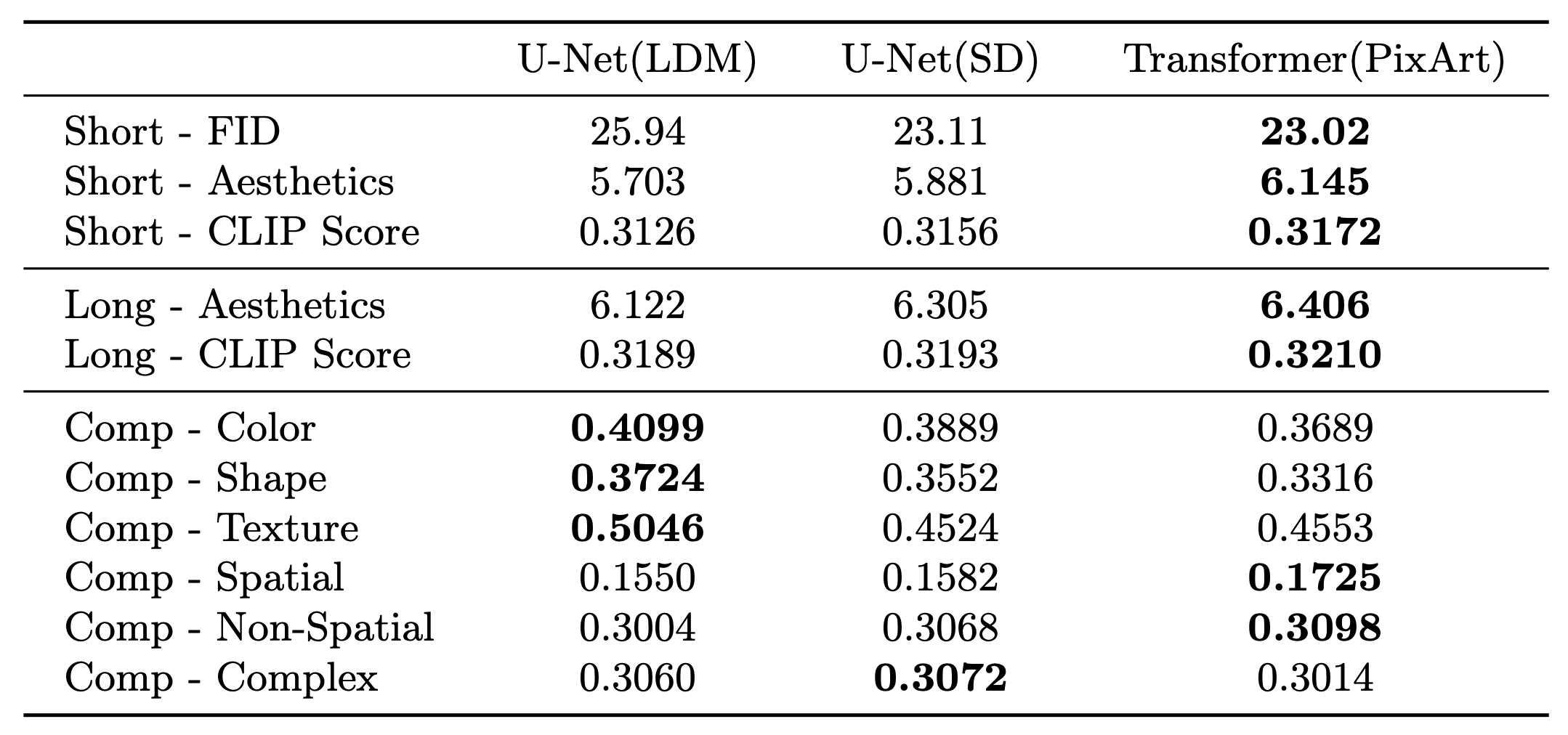
We conducted the quantitative evaluation for LaVi-Bridge with different vision models. The results are shown in the following table. We can observe that for all the metrics measuring image quality, LaVi-Bridge with the PixArt vision model achieves the best results. Additionally, the U-Net in Stable Diffusion, an enhanced version of the U-Net in the Latent Diffusion Model, still outperforms Latent Diffusion Model’s U-Net under LaVi-Bridge on image quality.
Here, we provide more visualization results of LaVi-Bridge with different combinations: CLIP+U-Net(SD), T5-Small+U-Net(SD), T5-Base+U-Net(SD), T5-Large+U-Net(SD), Llama-2+U-Net(SD), T5-Large+U-Net(LDM), T5-Large+Transformer(PixArt):

@article{zhao2024bridging,
title={Bridging Different Language Models and Generative Vision Models for Text-to-Image Generation},
author={Zhao, Shihao and Hao, Shaozhe and Zi, Bojia and Xu, Huaizhe and Wong, Kwan-Yee~K.},
journal={arXiv preprint arXiv:2403.07860},
year={2024}
}